Multi-format publishing and re-purposing of historical linguistics data
Helena Bermúdez Sabel
University of Neuchâtel
Outline
- Introduction
- the WoPoss project as a use case
- research question and goals
- An open science workflow
- Multi-format publishing as a re-usability strategy
Introduction
The WoPoss project
- A world of possibilities. Modal pathways over an extra-long period of time: the diachrony of modality in the Latin language . SNF project n° 176778
- The team:
- PI: Francesca Dell’Oro
- Senior researcher: Helena Bermúdez Sabel
- PhD student and project assistant: Paola Marongiu
The WoPoss project
- Research question: how have Latin modal markers evolved during a long period of time (1000 years)?
- Method: automatic linguistic annotation + manual semantic annotation of a representative corpus
WoPoss as an extrapolable use case
- Generic goals
- to have an annotated corpus that is useful and shareable
- to have a GUI that is useful and intuitive
WoPoss as an extrapolable use case
- Generic challenges
- source text retrieval: copyright, philological quality, heterogeneity of formats
- preprocessing: orthographic variants, typographical conventions, abbreviations, editorial information
- annotation: pipeline, tool-dependency, formats
- publication: formats
An open science workflow
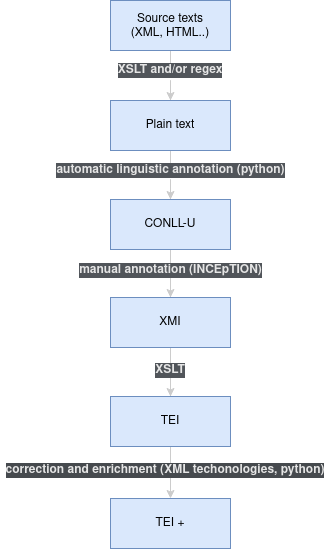
Corpus preparation
- Text retrieval (online, open-source)
- Homogenization

Source example: TEI-Epidoc
Source example: HTML
From “anything” to plain text
- Analysis of each file
- Conversion of typographical conventions and/or markup to pseudo-markup
- Plain text output
Automatic linguistic analysis
- Input: plain text
- Method: StanfordNLP library for Python (Stanza)
- Output: CONLL-U

CONLL-U
Manual annotation
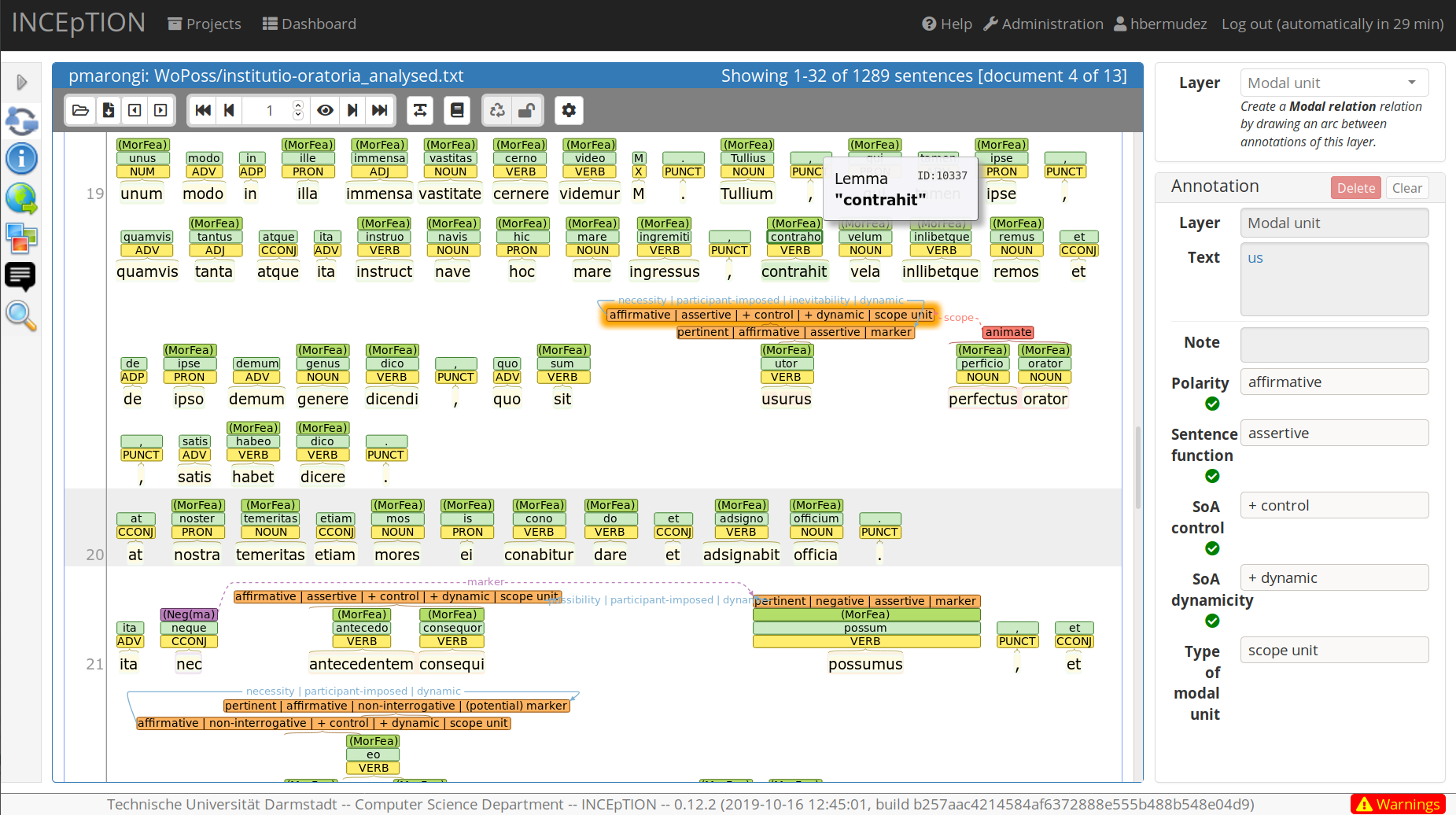
Output: UIMA CAS XMI
- Exportation of results of annotation process: UIMA CAS XMI
- Unstructured Information Management Applications: standard for annotation
- Feature structures are represented in the UIMA Common Analysis Structure (CAS)
XMI snippets




From XMI to TEI
- More widespread format than UIMA CAS in the DH community
- More suitable for editorial information


Correction and enrichment
- Validation of the annotation
- Correction of textual issues
- Transformation of pseudo-markup into TEI elements
- Addition of metadata (DHTK, Picca & Egloff 2017)
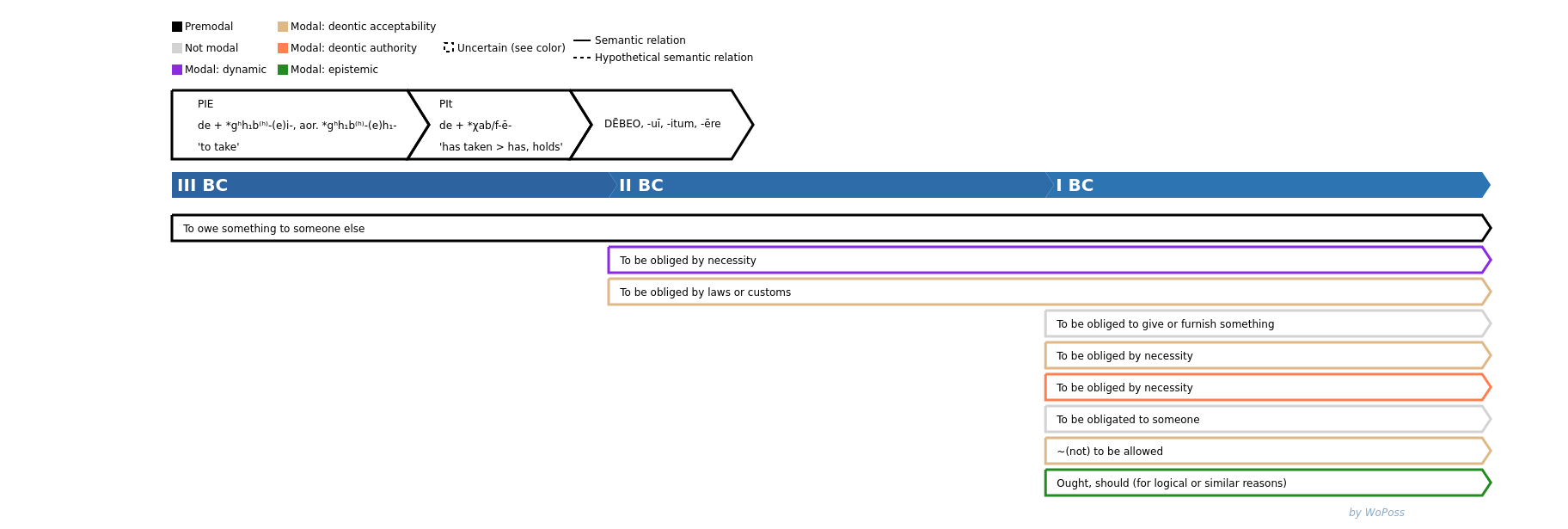
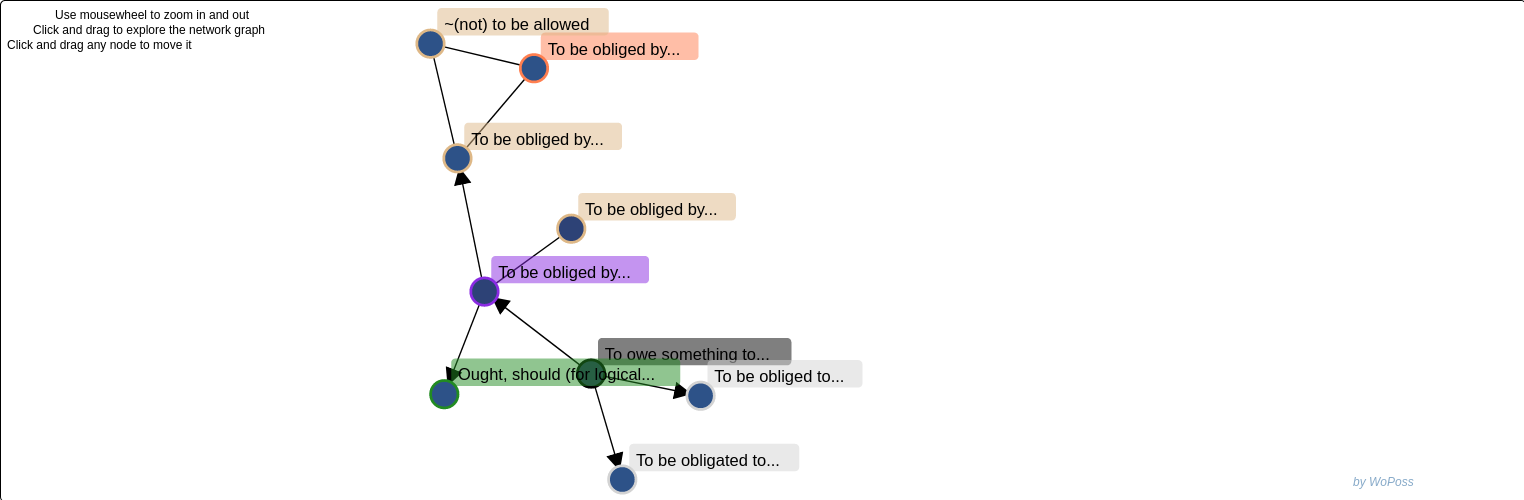
Diachronic semantic maps
of modal markers
- Initial source: synthesis of lexicographical works
- To be reviewed with the results of the corpus-based, empirical analysis
Multi-format publishing
as a re-usability strategy
Resource sharing
- Datasets
- Diachronic modal semantic maps in JSON, SVG and PNG. Interactive version online
- Plain text version of the source texts
- Automatic annotation results in CONLL-U format
Resource sharing
- Datasets
- Manual semantic annotation results in:
- UIMA CAS XMI
- TEI
- RDF/XML (see LiLa: Linking Latin)
- Manual semantic annotation results in:
- GUI
- Web application
- GUI-based access to the dataset and analysis functions as an eXist-DB application
Conclusions
Multi-format publishing
for different specialist groups
- Use of standardized formats in the workflow
- External software dependencies: free and open source
- Creation of customized programs tailored to the project specifications: open source
- Open science workfow and FAIR principles (both during development and results)
Thank you!
https://woposs.unine.chhttps://woposs.unine.ch/outputs/EADH2021/slides.html